[구성도]

- 최종 연동 목표
Kafka Connect 서버 VM <-> CDB PostgreSQL과 Apache Kafka 연동 <-> logstash <> NCP Search Engine <> Kibana 대시보드
0. 네이버 클라우드 콘솔에서 CDB For PostgreSQL 서비스를 신청합니다.
1,2 대량 오픈데이터 Set 를 NCP CDB PostgreSQL로 Import 하는 방법입니다.
3. 네이버클라우드 콘솔에서 Cloud Data Streaming / Search Engine 서비스를 신청합니다.
4. Apache-Kafka-Bastion-VM에 필요한 프로그램 모두 설치, 프로세스 기동, 연동합니다.
5. Apache Kafka에 PostgreSQL이 정상 Streaming 하고 있는지 확인합니다.
6. DB에 데이터를 다시 대량 데이터를 Import 시킵니다. (CDC를 확인을 위함)
7. search engine kibana 대시보드 접속용 로드밸런서를 생성해줍니다.
8. Search Engine의 Kibana 대시보드에서 DB의 데이터셋이 조회되는지 확인합니다.
[생성 클라우드 자원]
- VPC 1개 <10.7.0.0/16>
- Subnet 2개 <pub-subnet 10.7.50.0/24> , <pri-subnet 10.7.51.0/24>
- Server VM 1개 <kjw-kafka-connect-bastion 10.7.50.6 , pub-subnet>
- CDB PostgreSQL 1개 <kjw-cdb-test 10.7.51.6 , pri-subnet, cdb private domain은 보안상 비공개>
- Data Streaming Service <kjw-cds-test>, <manager node 1개, pub-subnet, 10.7.50.7>,
<broker node 3개 pri-subnet, 10.7.51.7, 10.7.51.8, 10.7.51.9>
- Search Engine Service <kjw-se-test, pri-subnet>
kjw-se-test-m-2myp 10.7.51.11 운영중 Manager kjw-pri-cdb | KR-1 | Private
kjw-se-test-m-2myq 10.7.51.12 운영중 Manager kjw-pri-cdb | KR-1 | Private
kjw-se-test-d-2myr 10.7.51.13 운영중 Data kjw-pri-cdb | KR-1 | Private
kjw-se-test-d-2mys 10.7.51.14 운영중 Data kjw-pri-cdb | KR-1 | Private
kjw-se-test-d-2myt 10.7.51.15 운영중 Data kjw-pri-cdb | KR-1 | Private
cds의 manager node를 왜 pub에 생성했냐고 궁금할 수도 있다.
또한, 각 서비스 별로 Subnet을 생성하지 않았냐고 궁금할 수도 있다.
단순한 이유론 개인적인 테스트를 빠르게 하기 위해서 pub-subnet / pri-subnet에 자원을 몰아서 생성했습니다.
고객사 제공용으로 구축 했으면 cdb 용 private-subnet 1개, cds 용 private subnet을 2 개 별도로 만들고,
Public에 접근할 필요가 없다고 판단이 되는 자원들은 Private Subnet에 생성할 것입니다.
[서비스 포트]
| 서비스 | 노드 | 포트 | 포트포워딩 | 용도 |
| Kafka | Broker | 9092 | x | Broker Port |
| Broker | 9093 | x | Broker TLS Port | |
| Manager | 2181 | x | Zookeeper Port | |
| Manager | 9000 | x | CMAK Port |
| 서비스 | 노드 | 포트 | 포트포워딩 | 용도 |
| Search Engine | Manager | 5601 | 80 | Kibana Dashboard Port |
| Broker Port | 9200 | - | Broker Port | |
| Manager, Broker | 9300 | - | S.E Nodes Internal Communication Port |
| 서비스 | 노드 | 포트 | 포트포워딩 | 용도 |
| CDB For PostgreSQL | PostgreSQL Standalone | 5432 | PostgreSQL Service Port |
[Inbound 방화벽 ACG]
추가 설정된 Inbound 방화벽 룰셋
| ACG명 | 접근 소스 | 허용 포트 | 메모 | 비고 |
| cdss-m-xxxxxx | 10.7.50.6/32 | 9200 | for Kafka bastion Server | cdss 생성 시 ACG 자동 생성됨 |
| cdss-b-xxxxxx | 10.7.50.6/32 | 9200 | for Kafka bastion Server | cdss 생성 시 ACG 자동 생성됨 |
| 10.7.50.6/32 | 9092 | for Kafka bastion Server | cdss 생성 시 ACG 자동 생성됨 | |
| searchengine-m-xxxxxx | 10.7.50.6/32 | 9200 | for Kafka bastion Server (logtash)) |
cdss 생성 시 ACG 자동 생성됨 |
| cloud-postgresql-xxxxxx | 10.7.50.6/32 | 5432 | for Kafka bastion Server (postgres) |
CDB 생성 시 ACG 자동 생성됨 |
| kjw-kafka-connect-bastion | X.X.X.X/32 | 22 | 사무실 공인 IP | kjw-kafka-connect-bastion-VM 용 ACG (수동생성) |
[Outbound 방화벽 ACG]
| kjw-kafka-connect-bastion | 0.0.0.0/0 | 1-65535 | Outbound ALL Open | kjw-kafka-connect-bastion-VM 용 ACG (수동생성) |
0. 네이버 클라우드 콘솔에서 CDB For PostgreSQL 서비스를 신청합니다.
CDB는 별다른 설정 없이 생성했으며, 아래 캡처 참고 부탁드립니다.
최소사양은 2vCore 4GB이나, 저는 2vCore 8GB로 생성해주었습니다.
DB 유저명 kang, DB 명은 aiport로 생성했습니다.

CDB > DB Service 상세보기 > DB User 관리에서, kang 유저를 Replication Role Y로 설정해주었습니다.

1,2 대량 오픈데이터 Set 를 NCP CDB PostgreSQL로 Import 하는 방법입니다.
1. Server VM에 Object Storage를 마운트하기 위해서는 s3fs 를 서버에 설치해야합니다.
# 사전 패키지 설치
yum install -y automake fuse fuse-devel gcc-c++ git libcurl-devel libxml2-devel make openssl-devel
# git 으로 가져오기
git clone https://github.com/s3fs-fuse/s3fs-fuse.git
# s3fs 설치
cd s3fs-fuse && ./autogen.sh
# configure
./configure
# make
make
# make install
make install
# /etc/passwd-s3fs 파일을 생성해 줍니다.
# "API Access Key":"API Secret Key"에 네이버클라우드 포털 계정에서 발급받은 API 키를 입력해주세요.
vi /etc/passwd-s3fs
'''
"API Access Key":"API Secret Key"
'''
wq 로 내용 저장
- 파일 권한 수정
chmod 600 /etc/passwd-s3fs
- 제 Object 버킷명은 kjw-postgresql-csv-test이고, 서버 내에선 /s3fs 경로로 마운트해보도록 하겠습니다.
NCP Object Storage Endpoint는 공공 수도권이고, GOV의 수도권 오브젝트 사설 도메인은 https://kr.object.private.gov-ncloudstorage.com 입니다.
클라우드 트래픽이 요금이 우려되어, S3 사설 도메인을 연결해주었습니다.
아예 발생되지 않는건 아닙니다. Object Storage가 VPC로 사설 통신을 보낼 때, 1G 당 20원이 발생된다고 합니다.
- Public Subnet/Private Subnet에 구축된 서버의 S3 Endpoint 값
수도권 Endpoint
공인 도메인: https://kr.object.gov-ncloudstorage.com
사설 도메인: https://kr.object.private.gov-ncloudstorage.com
남부권 Endpoint
공인 도메인: https://krs.object.gov-ncloudstorage.com
사설 도메인: https://krs.object.private.gov-ncloudstorage.com
- s3fs 디렉터리를 생성해줍니다.
mkdir /s3fs
# NCP Object 스토리지를 Server VM에 마운트 합니다.
# 명령어 예시
s3fs kjw-postgresql-csv-test [로컬 마운트 경로] \
-o passwd_file=[API 키 파일위치] \
-o url=[ncp object storage endpoint] \
-o use_path_request_style \
-o dbglevel=info
# 명령어
s3fs kjw-postgresql-csv-test /s3fs \
-o passwd_file=/etc/passwd-s3fs \
-o url=https://kr.object.private.gov-ncloudstorage.com \
-o use_path_request_style \
-o dbglevel=info
- 서버 재부팅 시에도, /s3fs 에 *영구 마운트 되길 원하신다면 아래 설정을 /etc/fstab에 설정해 주세요.
# /etc/fstab 등록 형식
# 옵션 설명
# - fuse : fuse는 Filesystem in Userspace의 약자로, 커널 공간이 아닌 사용자 파일 시스템을 마운트할 수 있게 해주는 기술입니다. s3fs는 fuse기반으로 동작하기에, 이 옵션이 명시되어야합니다.
# - _netdev : 네트워크 기반의 파일 시스템(Network Device)임을 나타냅니다. ** 이 옵션은 파일 시스템이 네트워크 연결이 필요함을 시스템에 알려줍니다.
# - allow_root : 루트 사용자만 허용합니다. allow_others는 다른 사용자도 허용하기에 보안상 좋지 않습니다.
# - use_path_request_style : S3 API 요청 형식이 Deafault인데, Path-Style로 강제하는 옵션입니다. https://endpoint/bucketname/path/to/object 즉, 버킷 이름을 호스트네임에 포함하지 않고 URL의 **경로(Path)**에 포함시킵니다.
# - dbglevel=info : 로그 레벨 info로 지정 기본적인 정보 로그만 저장됨.
# s3fs#[버킷명] [서버 내 마운트 위치] fuse _netdev,allow_other,passwd=[apikey 암호파일위치],url=https://[naver cloud object storage private domain]
아래 명령어는 서버에서 마운트 했을 당시 진행했던 명령어입니다.
s3fs#kjw-postgresql-csv-test /s3fs fuse _netdev,allow_root,passwd_file=/etc/passwd-s3fs,url=https://kr.object.private.gov-ncloudstorage.com,use_path_request_style,dbglevel=info 0
- s3fs 이 마운트된 것을 볼 수 있습니다.

- kjw-postgresql-csv-test 버킷 내부에 엑셀 파일도 보이고, test 폴더도 보이네요

- 저는 네이버클라우드 오브젝트 스토리지에 airports.data.csv 파일의 대량 데이터파일을 올려서
NCP CDB For PostgreSQL에 대량 데이터들을 import 시킬겁니다.
그렇게 하려면, 인터넷에서 대량 데이터를 먼저 다운로드 받아야 합니다.
아래 사이트에 접속해주세요 OpenFlights: Airport and airline data
OpenFlights: Airport and airline data
언어 Deutsch (de) English (en) español (es) français (fr) italiano (it) lietuvių (lt) Nederlands (nl) polski (pl) português (pt) suomi (fi) svenska (sv) русский (ru) 中文 (zh) 日本語 (ja) 한국어 (ko)
openflights.org
아래 airports.dat 파일을 클릭해서 다운로드 받고 NCP object storage에 업로드해주세요~

PostgreSQL 의 데이터베이스 명은, aiport이고, 스키마 명은 airport_schema,
테이블 명은 airport_information 으로 생성해 주었습니다.
-- kafka-connect-bastion-VM에 PostgreSQL을 설치해줍니다.
-- CDB PostgreSQL에 원격 접속을 위한 postgresql 클라이언트 설치입니다.
yum install -y postgresql
-- DB 스키마, 테이블 생성
- bastion-host vm에서 psql 에 접속합니다.
psql -h <CDB Private Domain> -U <DB_USER> -d <Database_Name>
- postgresql에서 아래 쿼리를 실행합니다.
- aiport_schema를 생성해줍니다.
CREATE SCHEMA airport_schema;
- airport_infromation를 생성해줍니다.
CREATE TABLE airport_schema.airport_information (
airport_id character varying(100),
airport_name character varying(100),
city character varying(100),
country character varying(100),
idata character varying(100),
icao character varying(100),
lat character varying(100),
lon character varying(100),
lttud character varying(100),
tmzon character varying(100),
dst character varying(100),
db_tmzon character varying(100),
type character varying(100),
source character varying(100)
);
- 오브젝트 스토리지로부터 아래 명령어를 통해 PostgreSQL로 DATA Import 합니다.
# 명령어 형식
\copy airport_schema.airport_information FROM '<서버 내 S3 마운트 위치>/{데이터파일.csv}' DELIMITER ',' CSV HEADER;
# 사용 명령어
\copy airport_schema.airport_information FROM '/s3fs/airports.dat.csv' DELIMITER ',' CSV HEADER;
- DB 데이터가 Insert 되었는지 확인합니다.
SELECT * FROM airport_schema.airport_information;

3. 네이버클라우드 콘솔에서 Cloud Data Streaming / Search Engine 서비스를 신청합니다.
- CDS : 별도 설정없이 Config Group (또한) Default로 생성했으며, 아래 캡처 참고 부탁드립니다.
노드 사양은 테스트니까 최소 사양 2core 4GB로 생성해주었습니다.

- Search Engine : 별도 설정없이 Default로 생성했으며, 아래 캡처 참고 부탁드립니다.
노드 사양은 테스트니까 최소 사양 2core 4GB로 생성해주었습니다.

4번으로 넘어가기 전에, 위에 스크롤을 올리셔서
[방화벽 ACG] 내용을 확인하시고, 각 ACG별로 Inbound 방화벽 룰셋 세팅해 주세요..!
4. Apache-Kafka-Bastion-VM에 필요한 프로그램 모두 설치, 프로세스 기동, 연동합니다.
- kafka connect
- confluent-hub
- debezuim postgresql connector
- kafka-connect-jdbc
- elastic search connector
- logstash
1. kafka connect 설치
// NCP 매뉴얼 상에는, openjdk-1.8.0 버전 설치로 안내되어있지만,
Kafka Connect 프로세스 기동 시 java runtime 관련 에러가 발생하여 runtime 에러나지 않게
openjdk 11 버전으로 수동 설치해주었습니다.
- openjdk java 11 다운로드 / 설치
# java download && unzip tar file
wget -P /root https://download.java.net/openjdk/jdk11/ri/openjdk-11+28_linux-x64_bin.tar.gz && tar xvfz /root/openjdk-11+28_linux-x64_bin.tar.gz
# /etc/profile 수정
vi /etc/profile
'''
# java 경로 설정
export JAVA_HOME=/root/jdk-11
# 주의!! 다른 프로그램에서 별도 PATH를 설정해서 쓰시면 기존 설정이 날아가지 않도록 주의해주세요. 장애 발생합니다.
export PATH=$JAVA_HOME/bin:$PATH:/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
'''
# /etc/profile 적용
source /etc/profile
# java version 확인
java -version
'''
openjdk version "11" 2018-09-25
OpenJDK Runtime Environment 18.9 (build 11+28)
OpenJDK 64-Bit Server VM 18.9 (build 11+28, mixed mode)
'''
# javac 버전 확인
javac -version
'''
javac 11
'''
# java 환경 변수 확인
echo $JAVA_HOME && echo $PATH
# java 실행 위치 확인
which java
2 kafka connect 다운로드, 설치, 프로세스 기동
# 아래 명령어를 입력하여 서버의 /root 경로에 Kafka Connect를 다운로드, 압축해제해 주십시오.
wget -P /root http://packages.confluent.io/archive/7.0/confluent-community-7.0.1.tar.gz && tar -zxvf /root/confluent-community-7.0.1.tar.gz
# connect-distributed.properties 파일을 수정합니다.
vi /root/confluent-7.0.1/etc/kafka/connect-distributed.properties
'''
# Cloud Data Streaming Service의 브로커 노드 정보를 참고하여 connect-distributed.properties 파일 내용에 ‘bootstrap.servers’에 ip 목록을 추가합니다.
bootstrap.servers=10.7.51.7:9092,10.7.51.8:9092,10.7.51.9:9092
'''
# Kafka Connect 프로세스 기동
/root/confluent-7.0.1/bin/connect-distributed -daemon /root/confluent-7.0.1/etc/kafka/connect-distributed.properties
# 8083 포트가 올라왔는지 확인합니다.
netstat -tnlp | grep 8083
# 에러가 발생했다면, 프로세스 기동 시 -daemon 옵션을 빼고 기동해주시고, 로그 분석하셔서 해결하면 됩니다.
3. Confluent Hub 설치
# 아래 명령어를 입력하여 /root 경로에 새로운 폴더를 만든 후 해당 폴더로 이동해 주십시오.
mkdir /root/confluent-hub && cd /root/confluent-hub
# confluent-hub를 다운로드, 압축 해제합니다.
wget -P /root/ http://client.hub.confluent.io/confluent-hub-client-latest.tar.gz && tar -zxvf /root/confluent-hub-client-latest.tar.gz
# 현재 경로(/root/confluent-hub)에 추후 플러그인이 저장될 폴더를 생성해 주십시오.
mkdir -p /root/confluent-hub/plugins
# 아래 내용을 입력하여 PATH 환경변수에 압축 해제한 bin 폴더의 경로를 추가해 주십시오.
# 기존 PATH 환경변수는 유지하고, 아래의 내용만 추가해주면 됩니다.
vi /etc/profile
'''
export PATH=$JAVA_HOME/bin:$PATH:/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
# Confluent HUB PATH 환경변수 내용 추가
export CONFLUENT_HOME='~/confluent-hub'
export PATH=$PATH:$CONFLUENT_HOME/bin
'''
# 환경 변수를 로드합니다.
source /etc/profile
# confluent-hub 명령어 실행 위치를 확인합니다.
which confluent-hub
'''
/root/confluent-hub/bin/confluent-hub
'''
4. debizium postgresql connector 설치
- confluent-hub 명령어를 통해 debizium postgresql connector를 설치해줍시다.
confluent-hub install debezium/debezium-connector-postgresql:latest --component-dir /root/confluent-hub/plugins --worker-configs /root/confluent-7.0.1/etc/kafka/connect-distributed.properties
5. kafka-connect-jdbc 설치
- confluent-hub 명령어를 통해 kafka-connect-jdbc 를 설치해줍다.
confluent-hub install confluentinc/kafka-connect-jdbc:latest --component-dir /root/confluent-hub/plugins --worker-configs /root/confluent-7.0.1/etc/kafka/connect-distributed.properties
6. elastic search connector 설치
- confluent-hub 명령어를 통해 elastic search connector 설치해줍니다.
confluent-hub install confluentinc/kafka-connect-elasticsearch:11.1.3 --component-dir /root/confluent-hub/plugins --worker-configs /root/confluent-7.0.1/etc/kafka/connect-distributed.properties
7. kafka connect 프로세스를 재기동 해야합니다.
# 기동중인 kafka connect 프로세스 kill
kill -9 $(netstat -tnlp | grep 8083 | awk '{print $7}' | cut -d'/' -f1)
# kafka connect 프로세스 기동
/root/confluent-7.0.1/bin/connect-distributed -daemon /root/confluent-7.0.1/etc/kafka/connect-distributed.properties
8. confluent-hub 명령어를 통해 plugins들이 정상 설치되었는지 확인합니다.
# jq command not found가 뜬다면, yum install -y jq 진행.
curl localhost:8083/connector-plugins | jq
-----
[
{
"class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"type": "sink",
"version": "11.1.3"
},
{
"class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"type": "sink",
"version": "10.7.3"
},
{
"class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"type": "sink",
"version": "10.8.0"
},
{
"class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"type": "source",
"version": "10.7.3"
},
{
"class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"type": "source",
"version": "10.8.0"
},
{
"class": "io.debezium.connector.postgresql.PostgresConnector",
"type": "source",
"version": "2.5.4.Final"
},
{
"class": "org.apache.kafka.connect.mirror.MirrorCheckpointConnector",
"type": "source",
"version": "1"
},
{
"class": "org.apache.kafka.connect.mirror.MirrorHeartbeatConnector",
"type": "source",
"version": "1"
},
{
"class": "org.apache.kafka.connect.mirror.MirrorSourceConnector",
"type": "source",
"version": "1"
}
]
-----
9. Debizuim PostgreSQL Connector를 이용해서, PostgreSQL과 Kafka 를 연동해줍니다.
// 주석 처리 된 부분은 부연 설명이니, 명령어를 진행하실 때 삭제하고 curl 진행해주세요.
// Connector를 잘못 설정하셧어도 걱정하지 않으셔도 됩니다.
# curl -X DELETE http://localhost:8083/connectors/{등록된 Connector 이름} 명령어로 삭제하면 됩니다.
curl -X PUT http://localhost:8083/connectors/postgresql-connector/config \
-H "Content-Type: application/json" \
-d '{
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "CDB Private Domain", // CDB PostgreSQL Service Domain
"database.port": "5432", // PostgreSQL Database Service Port
"database.user": "DB유저명", // PostgreSQL Database 사용자명, 제가 생성한 사용자명은 kang
"database.password": "DB패스워드", // PostgreSQL Database 패스워드
"database.dbname": "airport", // PostgreSQL Database 이름, 제가 생성한 DB 명은 airport
"database.server.name": "NCP_POSTGRESQL", // PostgreSQL Database 이름, 임의로 지정해도 됨.
"topic.prefix": "NCP_POSTGRESQL", // Apache Kafka에서 사용하는 Topic 이름, 추후 Kafka의 Topic의 맨 앞 접두사로 붙으니 이름은 원하시는 규칙대로 설정
"table.include.list": "airport_schema.airport_information", // {PostgreSQL_Schema}.{PostgreSQL_Table} 이름
"plugin.name": "pgoutput", // pgoutput은 PostgreSQL의 변경 데이터 캡처(CDC)를 수행할 때 사용하는 출력 플러그인입니다.
"slot.name": "debezium_slot", // PostgreSQL에서 데이터를 변경 이벤트로 캡처하고, Debezium이 이 슬롯을 통해 변경 사항을 읽습니다.
"publication.name": "debezium_pub", // Publication은 PostgreSQL의 논리 복제 기능으로, 특정 테이블의 변경 사항을 외부 소비자(여기서는 Debezium)에 제공하는 역할을 합니다.
"database.history.kafka.bootstrap.servers": "10.7.51.7:9092,10.7.51.8:9092,10.7.51.9:9092", // Debezium이 테이블의 스키마 변경 사항(예: 컬럼 추가/삭제)을 저장할 Kafka 브로커를 설정합니다.
"database.history.kafka.topic": "db_history.airport", // 테이블 스키마 변경 이력을 기록하는 Kafka 토픽 이름입니다.
"snapshot.mode": "initial", // "initial": 처음 시작할 때 PostgreSQL 테이블 전체 데이터를 스냅샷으로 가져옵니다. 이후에는 변경 사항만 Kafka로 스트리밍됩니다.
"key.converter": "org.apache.kafka.connect.json.JsonConverter", // Kafka 메시지의 Key와 Value를 어떤 포맷으로 직렬화할지 결정합니다. , org.apache.kafka.connect.json.JsonConverter: 데이터를 JSON 형식으로 직렬화합니다.
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"database.sslmode": "disable" // PostgreSQL과의 연결 시 SSL 설정입니다. disable: SSL을 사용하지 않도록 설정합니다.
}'
이후, curl -X GET http://localhost:8083/connectors/postgresql-connector 명령어로 postgresql-connector의 상태를 확인해보시고, 상태가 DB Table Replication 관련 "failed" 라고 뜨신다면, DB에 접속해서 아래의 명령어를 쳐주세요.
# postgresql-connector 상태 확인
curl -X GET http://localhost:8083/connectors/postgresql-connector/status

아래 명령어를 진행해서 airport_schema.airport_information 테이블에 대한 변경 이벤트를 외부 소비자(예: Debezium과 같은 CDC 도구)에 공개(Publish) 하는 Publication을 생성합니다.
# DB 접속
psql -h pg-2vueb6.vpc-cdb-kr.gov-ntruss.com -U kang -d airport
# DB 공개 Publication 생성
CREATE PUBLICATION debezium_pub FOR TABLE airport_schema.airport_information;
# postgresql-connector 를 삭제 후 재생성해줍니다.
curl -X DELETE http://localhost:8083/connectors/postgresql-connector
# postgresql-connector 를 재생성해줍니다.
curl -X PUT http://localhost:8083/connectors/postgresql-connector/config \
-H "Content-Type: application/json" \
-d '{
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "CDB Private Domain",
"database.port": "5432",
"database.user": "kang",
"database.password": "DB패스워드",
"database.dbname": "airport",
"database.server.name": "NCP_POSTGRESQL",
"topic.prefix": "NCP_POSTGRESQL",
"table.include.list": "airport_schema.airport_information",
"plugin.name": "pgoutput",
"slot.name": "debezium_slot",
"publication.name": "debezium_pub",
"database.history.kafka.bootstrap.servers": "10.7.51.7:9092,10.7.51.8:9092,10.7.51.9:9092",
"database.history.kafka.topic": "db_history.airport",
"snapshot.mode": "initial",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"database.sslmode": "disable"
}'
# postgresql-connector 상태 재조회 시 Replication Failed 오류가 사라졌습니다.
curl -X GET http://localhost:8083/connectors/postgresql-connector/status
10. logstash 설치
- java-devel을 설치합니다.
yum install java-devel -y
- logstash를 /root 경로에 다운로드 후 압축 해제합니다.
# OpenSearch 용 logstash 버전으로 /root 경로에 다운로드 받았습니다.
wget -P /root https://artifacts.opensearch.org/logstash/logstash-oss-with-opensearch-output-plugin-7.16.3-linux-x64.tar.gz && tar xvfz /root/logstash-oss-with-opensearch-output-plugin-7.16.3-linux-x64.tar.gz
- /root/logstash-7.16.3/config/logstash.conf 파일은 존재하지 않으니 아래 내용으로 신규 생성합니다.
- 아래 내용 중 ${~} 안에 들어갈 내용은 수정하지 않으셔도 됩니다.
/etc/profile에 환경변수로 세팅하기 때문입니다.
추가적으로, search engine 매니저 노드가 이중화 되어있다면, 아래 내용으로 넣어주세요.
hosts => ["https://${ses_manager_node1_ip}:9200", "https://${ses_manager_node2_ip}:9200" ]
# logstash.conf 파일 생성
vi /root/logstash-7.16.3/config/logstash.conf
'''
input {
kafka {
bootstrap_servers => "${bootstrap_servers}"
topics => ["NCP_POSTGRESQL.airport_schema.airport_information"]
group_id => "logstash-group"
codec => json
}
}
output {
opensearch {
hosts => ["https://${ses_manager_node1_ip}:9200"]
index => "cdss-%{+YYYY.MM.dd}"
user => "${userID}"
password => "${password}"
ssl_certificate_verification => false
}
}
'''
- /etc/profile에 환경 변수를 세팅해줍니다.
# JAVA 환경 변수
export JAVA_HOME=/root/jdk-11/
export PATH=$JAVA_HOME/bin:$PATH:/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
# Confluent-HUB 환경 변수
export CONFLUENT_HOME='~/confluent-hub'
export PATH=$PATH:$CONFLUENT_HOME/bin
# logtash 환경변수
export LS_JAVA_HOME=/root/jdk-11
export bootstrap_servers="10.7.51.7:9092,10.7.51.8:9092,10.7.51.9:9092"
export ses_manager_node1_ip="10.7.51.11"
# 매니저 노드가 이중화 되어있다면, 아래 주석 해제처리
#export ses_manager_node2_ip="10.7.51.12"
export userID="kang"
export password="DB 유저 비밀번호"
# /etc/profile 환경 설정을 로드해줍니다.
source /etc/profile
# logstash.conf 파일의 문법 검사를 진행합니다.
/root/logstash-7.16.3/bin/logstash --config.test_and_exit -f /root/logstash-7.16.3/config/logstash.conf
'''
conf 파일 내용에 이상이 없다면, 아래 내용이 출력됨.
Configuration OK
'''
# logstash 프로세스를 기동해줍니다.
# logstash 프로세스를 기동해줍니다.
nohup /root/logstash-7.16.3/bin/logstash -f /root/logstash-7.16.3/config/logstash.conf &
# 정상 기동 여부 확인을 위해서, /root/logstash-7.16.3/logs/logstash-plain.log 로그를 실시간으로 확인합시다.
tail -f /root/logstash-7.16.3/logs/logstash-plain.log
5. Apache Kafka에 PostgreSQL이 정상 Streaming 하고 있는지 확인합니다.
SELECT pid, usename, application_name, client_addr, state, sent_lsn, write_lsn, flush_lsn, replay_lsn
FROM pg_stat_replication;
CDB 이중화 구성이 되어있지 않을 때는, application_name에 Debizium Streaming 만 떠있는 것을 볼 수 있습니다.

* CDB 이중화 되어있으면 pgautofailover_replicator 도 조회되니 참고 부탁드립니다.
client_addr 10.7.51.14 는 CDB secondary 스탠바이 서버 사설 IP 입니다.


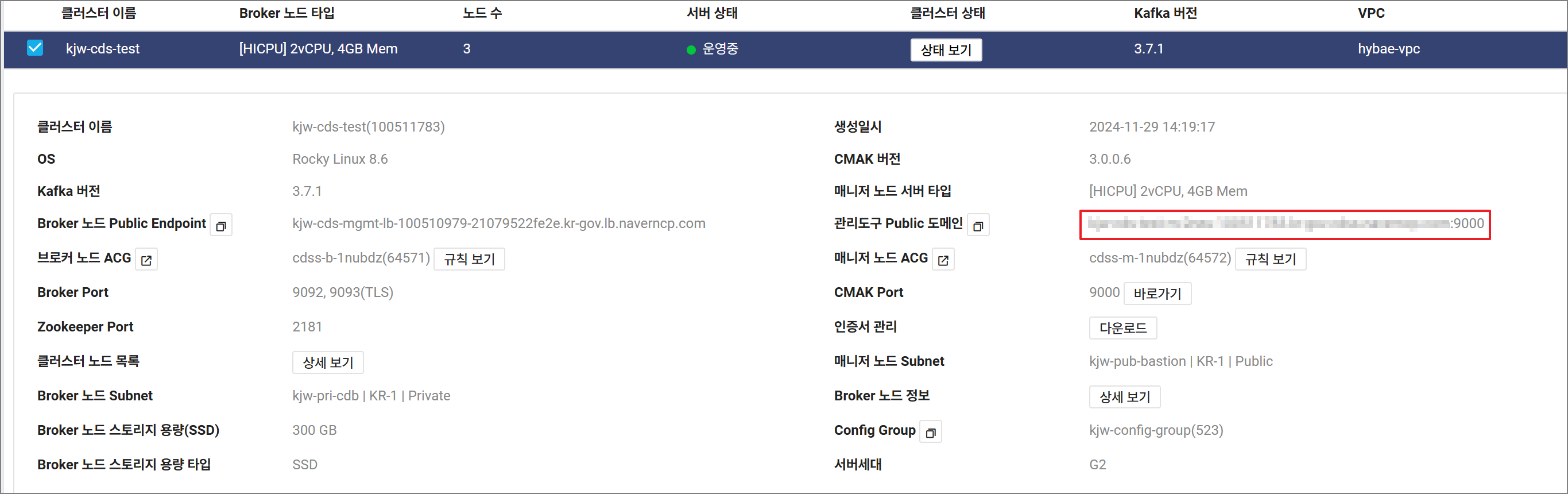
Apache Kafka의 CMAK 홈페이지를 활성화하기 위해서 NCP 콘솔에 로그인해주세요.
이후 Cloud Data Streaming Service > Cluster > 클러스터 관리 > 관리도구 접속 도메인 설정 변경을 클릭니다.

저는 이미 활성화가 되어있어 비활성화 여부를 물어보지만,
처음 클릭해서 들어오는 것이라면 비활성화 > 활성화 여부를 진행하는 것이니, 확인 눌러주시면 됩니다.

CDS의 관리도구 Public Domain 링크를 접속하시면 CMAK 홈페이지가 열립니다.
CDS를 생성했을 때 CMAK 계정을 설정가능하고, 접속 정보를 잊으셨다면
네이버 콘솔에서 CDS 매뉴를 통해 변경 후 접속해주세요
apache kafka CMAK 사이트에서 NCP_POSTGRESQL.airport_schema.airport_information Topic이 생성되었는지 확인합니다. 대용량 테이블이 들어가있다보니, 바로 생성이 되지 않았네요 토픽이 표시되는데 5분정도 걸렸습니다.

이왕 Topic이 생성된 김에 Kafka에서 Topic 상태 점검을 해봅시다.
# NCP_POSTGRESQL.airport_schema.airport_information Topic의 파티션 상태를 조회합니다.
./kafka-topics.sh --bootstrap-server 10.7.51.7:9092 --describe --topic NCP_POSTGRESQL.airport_schema.airport_information
NCP_POSTGRESQL.airport_schema.airport_information 토픽에 대해 파티션 3개가 있으며, 각각의 파티션에 리더가 정상적으로 지정되어 있는 것을 확인할 수 있습니다. 이 상태라면 Kafka 토픽은 제대로 설정되어 있는 것으로 보입니다.

# Kafka 토픽의 Consumer 그룹 리스트도 조회해 봅시다.
./kafka-consumer-groups.sh --bootstrap-server 10.7.51.7:9092 --list
총 3개의 Consumer 그룹 리스트가 보입니다. 64834, 22388는 조회해도 Active 가 된 그룹이라고 나오지 않습니다.
KMOffset가 실제 서비스 Consumer Group 이라고 추측됩니다.
해당 부분은 확인 후 내용 업데이트 하도록 하겠습니다.

# 아래의 명령어로 DB 데이터가 있는지 조회합니다.
당황하지 마세요! 쉘에서 아무리 기다려도 무반응으로 나오는 것이 맞습니다.
이유는 저희가 등록한 Apache Kafka는 CDC (Change Data Capture) 방식으로 변경되는 데이터를 캡처합니다.
저희는 0번에서 미리 DB 데이터를 넣어줬었죠? 그래서 데이터 변경 캡처가 없으니 무반응이 맞는겁니다.
/kafka-console-consumer.sh --bootstrap-server 10.7.51.7:9092 --topic NCP_POSTGRESQL.airport_schema.airport_information --from-beginnin
방법은 다시 CDB PostgreSQL에 접속하신 후 오브젝트 스토리지에 있는 데이터를 다시 덮어씌우면 됩니다~!
6. DB에 데이터를 다시 대량 데이터를 Import 시킵니다. (CDC를 확인을 위함)
# CDB PostgreSQL 접속
psql -h [PostgreSQL CDB Access Domain] -U kang -d airport
# 기존 DB 데이터 덮어 씌우기
\copy airport_schema.airport_information FROM '/s3fs/airports.dat.csv' DELIMITER ',' CSV HEADER;
# CDC 변경 데이터 확인해보기
./kafka-console-consumer.sh --bootstrap-server 10.7.51.7:9092 --topic NCP_POSTGRESQL.airport_schema.airport_information --from-beginning
너무~~ 많은 CDC가 조회가 됩니다. 중간에 CTRL+C로 끊었습니다.

7. search engine kibana 접속용 로드밸런서를 생성해줍니다.
NCP Elastic Search Kibana 대시보드에 접속하기 위해서는, 로드밸런서
Public 로드밸런서를 생성하고, 이의 공인 IP를 통해 접속을 해야합니다.
- NCP 매뉴얼 링크
Kibana/Opensearch 활용 (ncloud-docs.com)
Kibana/Opensearch 활용
guide-gov.ncloud-docs.com
우선, VPC → Subnet에서 elastic search 용 Public Subnet을 생성해줍니다.

로드밸런서 → 애플리케이션 로드밸런서 생성 → Public 로드밸런서를 생성해줍니다.
로드밸런서 URL을 통해서 kibana 대시보드 홈페이지에 접속해야하니까, 공인 IP도 함께 신청!!

80포트로 LB Listener 설정!

Target 그룹을 생성해 줍니다. 80포트로 search engine 의 manager 노드에 모두 넘겨주면 됩니다.

애플리케이션 로드밸런서를 생성을 마무합니다.

로드밸런서의 공인 IP 또는 LB URL 정보로 접속합니다.
Kibana 접속정보는 NCP Elastic Search 를 생성할 때 만든 정보로 로그인하시면 됩니다!
8. Search Engine의 Kibana 대시보드에서 DB의 데이터셋이 조회되는지 확인합니다.

대시보드를 생성해서 볼 것은 아니고, Dev tools로 확인해 볼겁니다. 눌러주세요

GET _cat/indices 로 검색 시 cdss 2024.12.13 이 보입니다.

cdss-2024.12.13 의 DB CDC 데이터를 보고싶을 때는 아래의 쿼리문을 실행합니다.
GET cdss-2024.12.13/_search
{
"query": {
"match_all": {}
}
}
DB 데이터가 json 형식으로 조회됩니다.

이상 네이버 클라우드에서 CDB PostgreSQL + Kafka Bastion VM + Data Streaming Service + Search Engine을 연동하는 방법에 대해 알아보았습니다.
감사합니다.
'Cloud > Naver Cloud Platform' 카테고리의 다른 글
| 작성중 - [NCP] Cloud Insight를 이용한 Cloud DB PostgreSQL 모니터링 설정 (2) | 2024.12.19 |
|---|---|
| [NCP] DATABASE MIGRATION SERVICE 소개 및 이용 방법 (2) | 2023.10.14 |

